Digital Media Lab public event 12 October 2023, 13.00-14.30, lokale 42.1-01, Roskilde Universitet
Danmarks Statistik skaber løbende nye, strukturerede data om
digitaliseringen i Danmark, der bl.a. kan fungere som et vigtigt ’reality
check’ for analyser af mere ustrukturerede data fra internettet. Vi får besøg
af to repræsentanter fra netop Danmarks Statistik, der fortæller om deres
arbejde på digitaliseringsområdet, og som også gerne vil have input fra
forskningsmiljøerne i forhold til vores behov og interesser fremadrettet.
Oplægsholdere: Agnes Tassy og Claus Werner Andersen,
Danmarks Statistik
All welcome – no registration needed – please share widely
Digital Media Lab event 20th April 2023, 11.30-12.45 in room 42.1-01, Roskilde University
Guest speaker: Anders Koed Madsen, Associate Professor & Head of Experiments, TANTLab, Aalborg University
An increasing number of scholars and students in the humanities and social sciences (SSH) are interested in what they can do with digital data and digital methods. At the same time, it can be challenging to pinpoint what skills must be honed to engage fruitfully with data from digital media. From coding via database management to visualisation and ethics, the requirements can seem wide-ranging and daunting. In this lab session, we set out to collectively understand and map the hands-on skill set that is key to get started with digital SSH. We have invited the Head of Experiments at TANTLab, Anders Koed Madsen, who has worked extensively with digital methods teaching and research. Anders will tell us about his experiences to get us started mapping the digital SSH skill set, which we can then continue to cultivate together in the Digital Media Lab at RUC.
As the extent to which digital technologies
already saturate societies is becoming apparent to growing numbers of global
citizens, the question of whether ubiquitous digitalization is desirable is
moving to the forefront of public debate: as we combat COVID-19, should contact
tracing apps and digital vaccination passports be mandatory for all citizens?
In the battle against crime, should facial recognition software be integrated
into surveillance equipment? Seeking to vanquish child abuse, should predictive
algorithms assist social workers’ case evaluation? These are but three of the
many issues that are being debated at present. And what about the (social)
media platforms on which these debates are conducted? Invoking freedom of
speech, should they remain unregulated? Seeking social justice, should hate
speech and incitement to violence be banned? As decision making and opinion
formation alike are becoming thoroughly digitalized, we need to discuss the
content of controversies about data and algorithms as well as the form of
datafied and algorithmic controversies.
A new research project aims to do just
that. Generously funded by the Villum and Velux Foundations, the Algorithms,
Data and Democracy-project will investigate issues of
public concern about digitalisation and datafication as these are shaped
by digital technologies and articulated in the digital
infrastructures of democracy. The aim is to understand current concerns and
challenges so as to be able to suggest ways in which the algorithmic
organisation of data can engage, enlighten and empower individual citizens and
democratic institutions. Turning potential crises of trust in democratic
societies as well as in novel technologies into opportunities for enhanced
digital democracy.
The ADD-project will achieve this aim through strong interdisciplinary
integration as well as disciplinary expertise. It brings together a team of researchers with unique
competences in computer science and technological research, the humanities and
the social sciences, building common theoretical and methodological approach in
the process of studying empirical cases. Further, the project integrates scientific research and public outreach by involving relevant
stakeholders and interested citizens from its outset and throughout the 10
years of its existence. At first, we will seek broad engagement, listening to concerns
and opinions of people and organizations. As we develop our research, we will seek
to enlighten the debate through the communication of results. Finally, we will
join in conversations that can empower citizens and inspire policy-makers to
instigate positive change.
Read more about the project on our website and follow it as it unfolds by subscribing to our
newsletter.
Article Author: Sander Andreas Schwartz, associate professor, IKH.
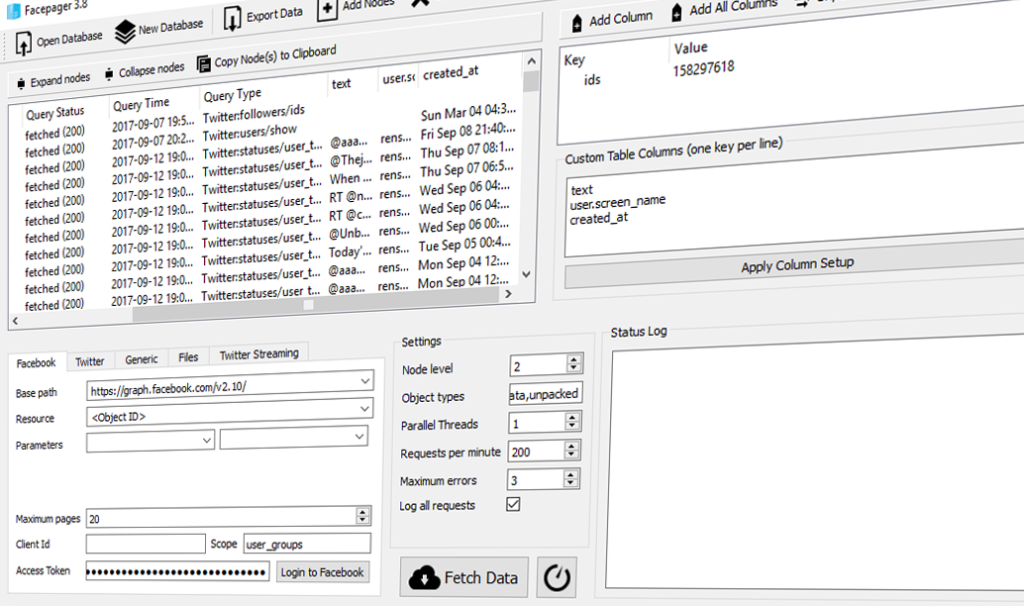
Picture from the public Facebook page of Facepager: https://www.facebook.com/facepagerpage
When researchers wish to collect data from social media platforms, they are often relying on the accessibility of the platform API, a system that allows a client to request for data and receive a structured response (See Lomborg and Bechman, 2014 for an explanation of how to utilize the API for research purposes). While the process of collecting data from the Facebook API was far from perfect (See Rieder et al., 2015), it was a rather efficient tool for big data collection. Recently, however, Facebook started to shut down the public access to the API leading some researchers to call this the APIcalypse (Bruns, 2019), while other argued that it was rather the “end of the Wild West” for social media research (Puschmann, 2019). In any case, collecting data from Facebook in through automated process have been difficult and uncertain over the last few years, leading the field into an uncertain future.
Recently there have been progress in this regard, as Facebook has provided various new options for data collection for research purposes. One option is the Crowdtangle solution, which allows researchers and other non-commerical actors to gain access to an officially supported platform for collection and analysis of Facebook and Instagram data. One of the major issues with this platform, is that it does not provide student access, making it virtually unusable for educational purpose. (if you are affiliated with a research team or project at RUC, you might be able to get access to our current subscription. Feel free to write us and ask).
But now we are happy to announce that there is in fact a publicly available tool for collecting public Facebook data that does not require any prior knowledge of programming. The tool is called Facepager, and this program will allow the collection of Facebook status updates form any public page as well as metadata about engagement metrics etc. The tool is not new as such, but after the APIcalypse as mention in the above, they have been granted public page access as the first publicly available research tool, making this a relatively new feature announced by the developer in late 2019 (link to tweet).
In order to get started, we recommend that you check out the walkthrough videos that they provide via their YouTube channel, starting with this: https://youtu.be/4f9yC4ug8ZU
In the coming months, we expect to explore Facepager more in detail, and potentially provide our own guide at DigitalMediaLab or even a workshop at the end of the semester. Please feel free to write us if you have any questions regarding this tool, and we shall do our best to answer your questions as we gain a deeper knowledge of the software.
Note: Facepager can actually be used to collect data from a variety API-based platforms as well as some web scraping even though Facebook is the primary feature.
References
Bruns, A. (2019). After the ‘APIcalypse’: Social media platforms and their fight against critical scholarly research. Information, Communication & Society, 1–23. https://doi.org/10.1080/1369118X.2019.1637447
Puschmann, C. (2019). An end to the wild west of social media research: A response to Axel Bruns. Information, Communication & Society, 1–8. https://doi.org/10.1080/1369118X.2019.1646300
Rieder, B., Abdulla, R., Poell, T., Woltering, R., & Zack, L. (2015). Data critique and analytical opportunities for very large Facebook Pages: Lessons learned from exploring “We are all Khaled Said.” Big Data & Society, 2(2), 205395171561498. https://doi.org/10.1177/2053951715614980
Kultur- og kommunikationsstudier af digitaliseringens omorganisering af hverdagen
Antologien Digitale liv. Brugere, platforme og selvfremstillinger, der er redigeret af Rikke Andreassen, Rasmus Rex Pedersen og Connie Svabo, samler en gruppe forskere om studiet af forskellige måder, hvorpå digitalisering påvirker menneskers liv og hverdag. De fleste af bidragyderne har fagligt hjemme på Institut for Kommunikation og Humanistisk Videnskab, og nogle af os (inklusiv undertegnede) er medlemmer af Digital Media Lab. Vi er altså alle kultur- og kommunikationsforskere med interesse for digitalisering, men snarere end et snævert fokus viser antologien feltets emnemæssige bredde, metodiske spændvidde og teoretiske eklekticisme. I denne omtale vil jeg give et overblik over de emner, metoder og teorier, som bogen rummer, og dermed en forsmag på, hvad man finder, hvis man dykker ned i den.
Den digitale hverdag
Hverdagen er blevet digital i en sådan grad,
at vi ikke tænker over det – indtil en del af den digitale infrastruktur bliver
synlig via et ’glitch’ i matrixens ellers så fejlfrie flow. Vi ser vores
afhængighed af det digitale, når internettet ’lacker’, som børnene råber med
lige dele vrede og resignation. Når iPhonen går i stykker, og det bliver
umuligt at holde styr på aftaler, at tage billeder, at lytte til musik og at komme
i kontakt med venner, for nu blot at nævne nogle af de funktioner, der i dag er
samlet i en smart phone. Eller når indkøbenes stregkode ikke kan scannes, og
man må vente på, at en af supermarkedets stadigt færre ansatte dukker op.
Bogens undertitel angiver tre overordnede
områder eller tematikker inden for denne omsiggribende udvikling, som bogen
også er struktureret efter. For det første ’brugere’. Hvad betyder det for os,
som individer og fællesskaber, at vi i stadigt stigende grad defineres i og med
de digitale teknologier, vi benytter os af? Når vi som borgere organiseres i
digitale offentligheder, finder vores nyheder på nettet og modtager information
fra ’det offentlige’ i e-boksen? Når byens rum bliver digitale og vores færdsel
i dem styres af vores evne eller vilje til at interagere med teknologierne
omkring os? Når computerspil florerer i stadigt flere undergenrer, og man fx
kan øve sig på kærlighed via spillene?
Det andet tema er ’platforme’. Her stilles
især skarpt på den algoritmiske opbygning af digitale infrastrukturer; hvordan
former de underliggende algoritmer brugernes handlemuligheder på fx Facebook,
Spotify og dating apps? Hvad betyder det, at interaktionen mellem bruger og
algoritme har en tendens til at virke forstærkende på brugerens smag? Altså,
når man både selv kan sætte sine præferencer og bliver tilbudt mere af den type
indhold, man efterspørger, er det på den ene side effektiv målretning, men på
den anden side også spildte muligheder. ’People who likes this, also liked…’-logikken
kan være en god måde at målrette indhold, men det kan også føre til ensporede
ekkokamre, til øget forudsigelighed og kontrol.
Endelig fokuserer det tredje tema
’selvfremstillinger’ på forskellige brugergruppers anvendelse af de
teknologiske muligheder til identitetsdannelse og/eller selvpromovering. Hvad
enten det drejer sig om influencere, der bliver berømte på at ’være sig selv’,
prekære arbejdere, der søger beskæftigelse via arbejdsplatforme, eller
professionelle organisationer, der bruger digital kommunikation som et middel
til realisering af strategiske mål, så formes individuelle og kollektive
identiteter i stadigt stigende grad af de digitale platformes mulighedsrum, og
i denne sidste del af bogen fokuseres der på, hvordan disse mulighedsrum
konkret udnyttes.
Digitale metoder?
Der er i antologien eksempler på, at den
omsiggribende digitalisering også skaber nye forskningspraksisser i form af
digitale metoder. Fx anvender Sander Andreas Schwartz i sit kapitel om
algoritmisk offentlighed ’walk-through’-metoden til at gennemgå Facebooks
design og funktionalitet, og i kapitlet om Spotifys anbefalingssystemer benytter
Rasmus Rex Pedersen sig af en ’kritisk læsning af algoritmen’, der muliggør en nærmere
undersøgelse af, hvordan anbefalingerne egentlig fungerer.
Det er dog karakteristisk, at ingen af
kapitlerne arbejder med digitale metoder til indsamling og analyse af ’big
data’. I stedet er fokus på kvalitative studier, ofte med særligt blik for
brugeren, hvad enten det er via kvalitative interviews, protokolanalyser eller
deltagerobservationer af brugeroplevelser eller gennem studier af individuelle
og kollektive aktørers digitale kommunikation. Antologien viser dermed, at digitaliseringen
ikke har overflødiggjort klassiske humanistiske og samfundsvidenskabelige
tilgange, men at det derimod i høj frad giver mening at studere de nye
fænomener med velkendte metoder.
Digital humaniora
Dermed bidrager kapitlerne med dybe og detaljerede indsigter i forskellige former for sociomateriel meningsdannelse; de forstår og forklarer ’digitale liv’ som måder, hvorpå teknologisk betingede handlerum opstår og udnyttes. Dette må være en af humanioras fornemste opgaver i dag; at forstå, hvad det vil sige at være menneske i en digital tidsalder – hvordan vi former vores digitale redskaber og hvordan de former os. Antologien bidrager med netop sådanne forståelser gennem inddragelse af en bred vifte af teoretiske perspektiver, modeller og begreber. Fra aktørnetværksteoretiske arrangementer af humane og non-humane aktører over digitale affordances til realiserede handlinger – og deres konsekvenser. Og fra kontrol, normalisering og forstærkning af eksisterende ideologiske rammer, fx via markedsliggørelsen af shitstorms, til kreativ udnyttelse af de etablerede rammer til afsøgning af mulige alternativer, fx gennem minoritetssubjekters selvkommercialisering.
Er man konkret interesseret i et eller flere af de temaer, som behandles i Digitale liv, eller mere generelt optaget af spørgsmålet om, hvordan teknologiske udviklinger påvirker menneskelige fællesskaber, er der masser af inspiration at hente i antologien. Som bagsideteksten lover, kan bogen ”læses af alle, der interesserer sig for den digitalisering, der i stigende grad præger vores samfund og digitale liv”.
Analysen er udført og skrevet af Sander Andreas Schwartz (lektor ved IKH) og Nicolaj Sveiger (Studentermedhjælp).
Den amerikanske valgkamp er ovre, og selvom efterspillet fortsætter, så står Biden til at bliver USAs næste præsident. I den forbindelse, så har Digital Media Lab valgt at kaste et blik på valgkampen på Facebook, for at se, hvordan de to præsidentkandidater præsterede på denne platform. Idéen med denne type analyser er, at vi på labbet kan præsenterer, hvordan digitale metoder og data kan anvendes i forbindelse med forskning. Analyser som nedenstående kan således ses som digitale eksperimenter der udforsker potentiale og værdi af digital data med henblik på dybere akademisk analyse i fremtiden.
For at hente og analysere data fra Facebook har vi i denne omgang gjort brug af CrowdTangle, som er Facebook’s officielt understøttede platform til indsamling og analyse af offentlige interaktioner fra sider og grupper (Læs mere om, hvilken data CrowdTangle indsamler her). Vi har indsamlet data fra Joe Biden og Donald J. Trumps officielle Facebooksider i de tre hele måneder op til valget i november, hvilket vil sige fra august til og med oktober. Dette giver os mulighed for at undersøge kandidaternes interaktioner i tre hele måneder i slutningen af valget for dermed at kunne sammenligne og studere deres aktivitet over tid. De tre måneder er valgt fordi august er den første hele måned efter Joe Biden officielt bliver udvalgt som demokraternes kandidat, og oktober er den sidste hele måned inden selve valgdagen den 3. november.
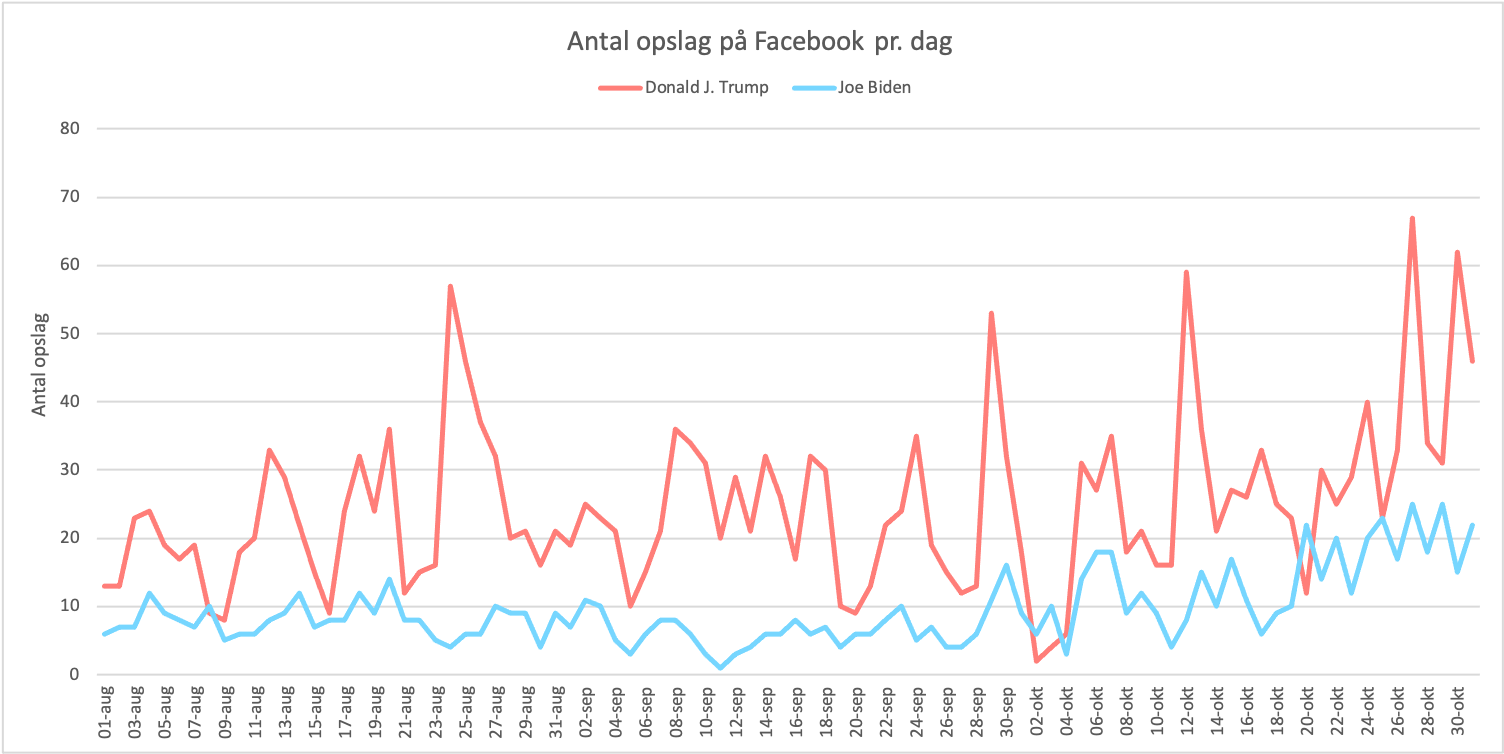
Det er ikke kun på Twitter, at Trump er meget aktivt. Når vi sammenligner antal statusmeddelelser i perioden 1. august 2020 til og med 31. oktober 2020 har Trump således lavet hele 2275 opslag på sin Facebookside, hvor Joe Biden i samme periode kun har lavet 874. I gennemsnit poster Trump således omkring 25 statusmeddelelser om dagen, men Biden kun poster 10. Der er tre dage i hele perioden, hvor Biden er mere aktiv end Trump, men i disse tilfælde skyldes det, at Trumps aktivitet falder ned på Bidens aktivitetsniveau, eksempelvist den 2. oktober, hvor Trump testes positiv og indlægges for Corona sammen med sin hustru (Se figur 1).
Figur 1 er baseret på antal opslag Donald J. Trump (rød) og Joe Biden (blå) har lavet på deres Facebooksider. Dataen er indsamlet i en tre måneders periode fra 1. august 2020 til og med 31. oktober 2020 amerikansk tid (EST). Data er indhentet via CrowdTangle
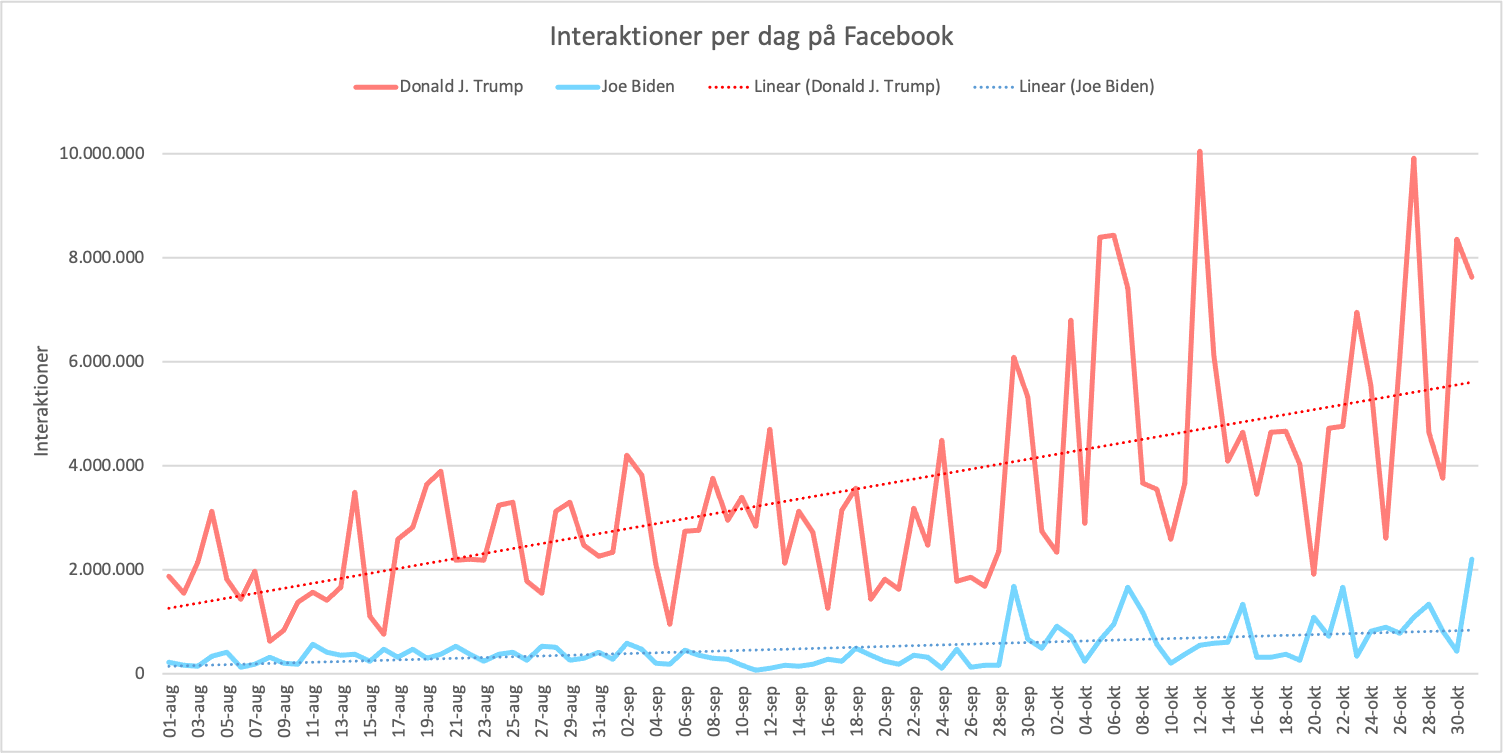
I perioden 1. august 2020 til 31. oktober 2020 har republikanske Donald J. Trump fået over 315 millioner interaktioner på de mange forskellige opslag på sin Facebook profil. Den demokratiske Joe Biden har fået tæt på 44,5 millioner interaktioner på sine opslag. Den dag Donald J. Trump fik færrest interaktioner var d. 8. august 2020 med kun 628.459 interaktioner. Joe Biden laveste antal interaktioner var d. 11. september 2020, hvor han på sine opslag kun fik 73.109 reaktioner. Omvendt var det højeste antal interaktioner d. 31. oktober 2020 hvor han fik 2.194.165 millioner interaktioner. Den dag Donald J. Trump havde flest interaktioner var d. 12. oktober 2020. Den dag lavede han hele 59 opslag. Opslagenes indhold var blandt andet skriftlige stikpiller til Joe Biden, men også opslag om aktiemarked og seertal for NBA-finalen. For Joe Bidens vedkommende var det få dage inden valget, d. 31. oktober 2020, hvor hans opslag fik flest interaktioner. Med 22 opslag om den tidligere præsident Barack Obama og Donald J. Trumps COVID-19 håndtering. Derudover ses det på grafen, at der er et stort spring fra den 28. til den 29. september ved Donald J. Trump. Det skyldes, at Donald J. Trump og Joe Biden var i deres første debat mod hinanden den 29. september. Vi ser i øvrigt samlet set, at Trumps interaktioner stiger gevaldigt over de tre måneder, hvis vi følger trendlinien, hvor Biden også ser en stigning, dog væsentligt mindre i proportion med hans generelle færre interaktioner (Se figur 2).
Figur 2 er baseret på antal interaktioner på Donald J. Trumps og Joe Bidens Facebook sider. Data er indsamlet i perioden 1. august 2020 til og med 31. oktober 2020 amerikansk tid (EST). Data er indhentet fra CrowdTangle.
Trumps mest engagerende post i perioden fra august til og med oktober er den 3. oktober fra sin sygeseng, hvor han skriver, at han har det godt og takker sine følgere. Denne post er således sammenlignelig med Mette Frederiksens besked fra sygesengen under det danske valg i 2019, men modsat hende, så laver Trump ikke en personlig video, men blot en statusmeddelelse på tekst (Se billede 1). Halvdelen af Trumps top ti mest engagerende posts er i øvrigt fra Trumps Corona-ophold på Walter Reed Medical Center.
Billede 1. Skærmbillede af post https://www.facebook.com/DonaldTrump/posts/10165550522915725
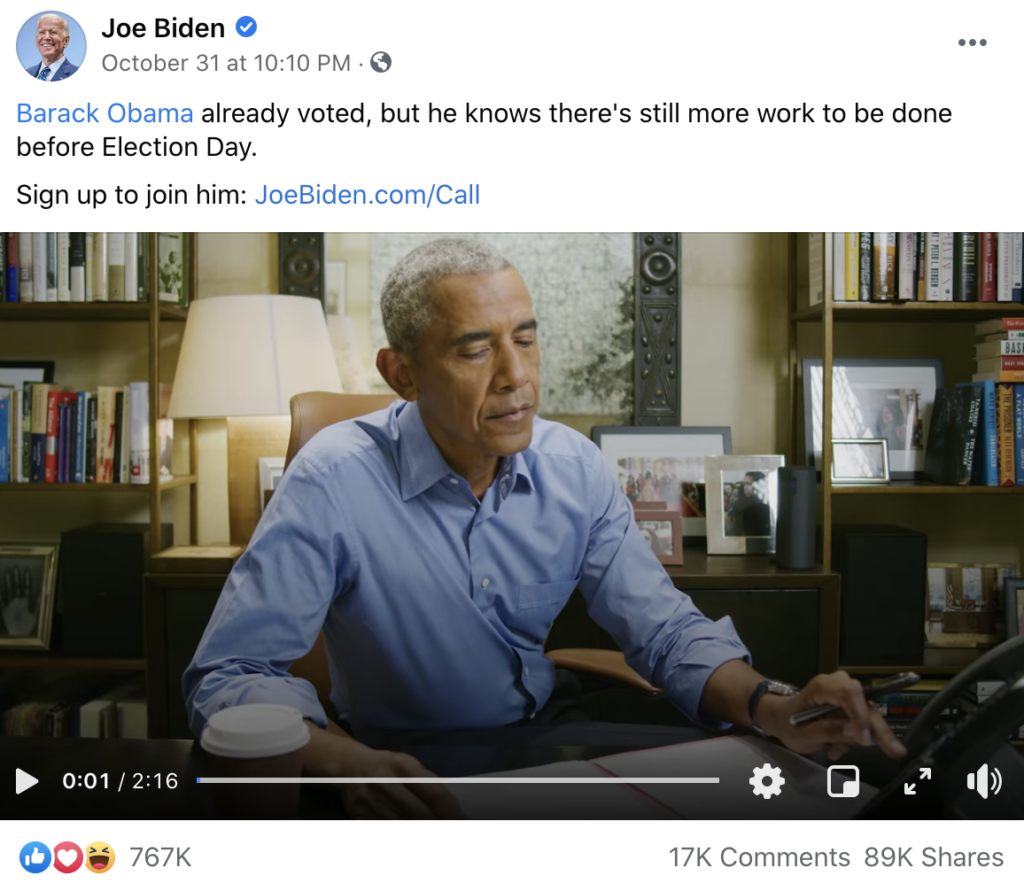
Omvendt er det måske sigende for Bidens kampagne på Facebook, at hans mest engagerende post i perioden fra august til og med oktober slet ikke har ham selv i fokus, men i stedet er en video med den tidligere præsident Barack Obama, som ringer til vælgerne for at få dem til at stemme på Joe Biden (Billede 2). Bidens andenmest engagerende post roser i øvrigt vicepræsidentkandidat Kamala Harris, og den tredjemest engagerende fordømmer Donald J. Trump.
BIllede 2. Skærmbillede af post https://www.facebook.com/joebiden/posts/10157651828676104
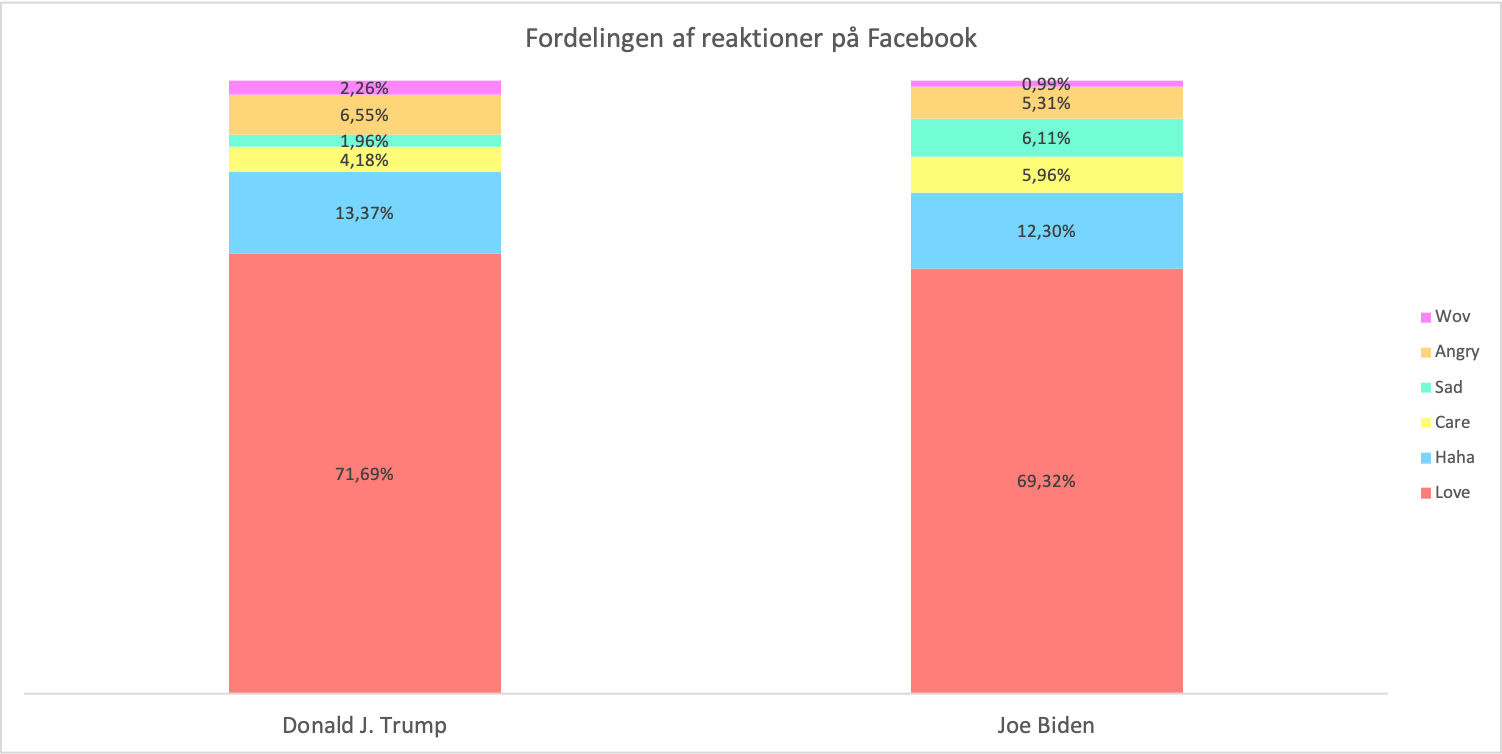
Det kunne tænkes, at Trumps tiltrækker mere engagement delvist baseret på en større skare af utilfredse vælgere baseret på hans kontroversielle og polarisende politik, samt hans position som hele landets daværende præsident. Dette kan vi lidt groft undersøge ved at se på mængden af følelsesreaktioner ud over den normale like-reaktion. Her ser vi faktisk at Trump og Biden har nogenlunde samme andel af ‘love’ reaktioner (72%/69%) samt ‘angry’ reaktioner (7%/5%). Ud over dette fordeler reaktioner sig nogenlunde på samme vis for begge kandidater ud over, at Biden har en lidt større andel af brugere, som reagerer på hans opslag med ‘sad’ (2%/6%). Baseret på denne undersøgelse er der således ikke noget der tyder på, at typen af engagement for hver følger er mærkbart anderledes fordelt på de to Facebooksider. Selvom en mere detaljeret undersøgelse af dette naturligvis kan nuancere dette overblik, så er det dog en indikator på, at både Trump og Bidens interaktioner i langt største grad baseres på folk, der er positivt indstillet overfor den pågældende sides ejer (Se figur 3).
Figur 3 er baseret på fordelingen af reaktioner (uden likes) på Donald J. Trump og Joe Bidens Facebooksider. Perioden er fra 1. august 2020 til og med 31. oktober 2020. Data er indhentet via CrowdTangle.
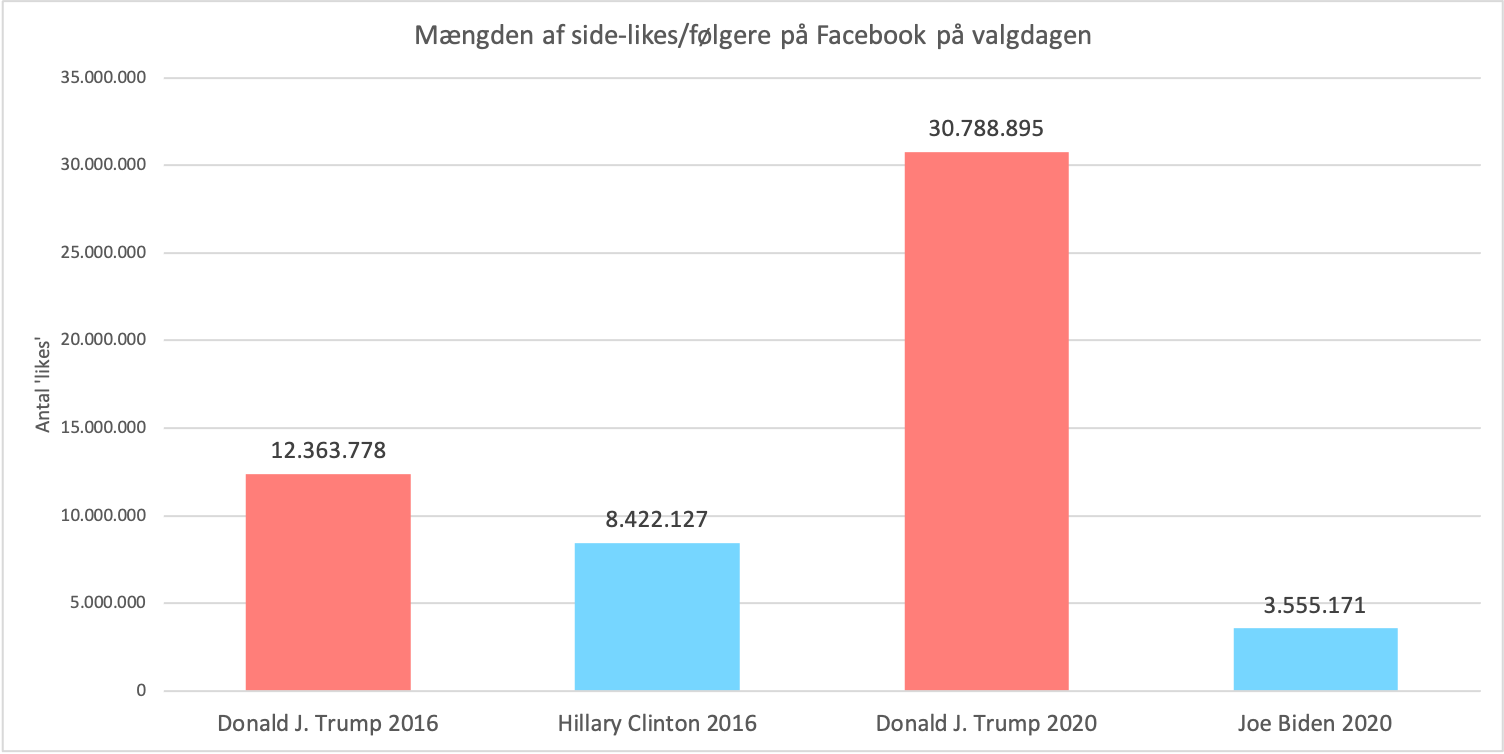
Lad os slutte med at se på, hvor mange følgere Facebooksiderne har, eftersom dette viser, hvor bredt siderne i udgangspunktet når ud til vælgerne. Her kan vi se på noget lidt anden data, da vi sammenligner side-likes, altså en Facebooksides følgere, for de to præsidentkandidater på selve valgdagen i 2020 sammenlignet med valgdagen tilbage i 2016. Som reality-stjene og celebrity, så slog Donald J. Trump allerede Hillary Clinton med flere sidelikes tilbage i 2016. Han slår også Joe Biden med længder i 2020, hvilket igen forklares af hans nu fire år som landets siddende præsident. Donald J. Trump har således boosted sin følgerskare fra 12.363.778 side-likes på valgdagen d. 8. november 2016 til 30.788.895 på valgdagen d. 3. november 2020. En stigning på 18.425.120 følgere, og en procentvis stigning på 149%. Her ses det ligeledes tydeligt, at Donald J. Trump er langt foran i forhold til sine politiske modstander begge år, men særligt i 2020, hvor Biden således har været gevaldigt bagude i hele perioden, når det kommer til synlighed og følgere på Facebook. Hillary Clinton havde på valgdagen i 2016 kun 8.422.127 følgere, og Joe Biden havde kun 3.555.171 følgere (Se figur 4).
Figur 4 er baseret på antallet af side-likes (følgere) på den enkelte Facebookside på valgdagen. For 2016 var valgdagen d. 8. november 2016. For 2020 var valgdagen 3. november 2020. Data er indhentet via CrowdTangle.
De ovenstående analyser giver et overblik over, hvor meget aktivitet og interaktion, der har været på begge kandidaters Facebooksider. Dette kan også bruges som en case på, hvordan Crowdtangle kan bidrage til forskning indenfor politisk kommunikation. Analysen af data fra Crowdtangle bør dog ikke stå alene af flere årsager. Den første og mest afgørende er naturligvis, at aktivitet og engagement på Facebook kun udgør en brik i den samlede kampagnestrategi for den enkelte politiker. Selvom Trump på papiret har været langt mere aktiv og tiltrukket langt mere engagement, så har han altså ikke formået at få flest stemmer i sidste ende. Det kan der naturlivis være flere årsager til, men én af dem er naturligvis, at success på sociale medier ikke kan vinde valget alene. Der er således ikke noget i denne data, der tyder på, at Biden har vundet valget baseret på hans anvendelse af sociale medier, men måske nærmere på trods af hans begrænsede engagement på disse platforme. Omvendt så må vi heller ikke tro, at denne data sammen med valgets resultater viser, at sociale medier ikke har nogen strategisk rolle. Tværtimod, så er det sandsynligt, at Donald Trump har haft stor gavn af sin stærke tilstedeværelse på sociale medier, eftersom sociale medier er en relativt billig platform for at nå ud til vælgere og mobilisere sine potentielle støtter.
Årets Amerikanske valgkamp er dog med til at understrege, at sociale medier ikke kan vinde valget alene. I stedet er dette et eksempel på en kandidat, som netop har været dygtig til at få det maksimale ud af sin tilstedeværelse på sociale medier, ud at dette dog kunne tippe vægtskålen til kandidatens fordel. Kommende undersøgelser vil nuancere, hvad der har været udslagsgivende for Trumps nederlag og Bidens sejr, men svaret skal nok ikke findes på sociale medier i denne valgkamp (læs en tidlig akademisk analyse af den amerikanske valgkamp på flere forskellige niveauer her).
Til allersidst kan man også stille spørgsmål tegn ved Crowdtangles data som kilde til at undersøge politikeres success på sociale medier. Der er nogle væsentlige begrænsninger ved denne data, særligt fordi Crowdtangle kun gør brug af offentlig tilgængelig data. Det betyder blandt andet, at vi ikke har adgang til reach, hvilket vil sige, hvor mange der er blevet eksponeret for den pågældende statusmeddelelse. Tallet for interaktioner (reaktioner, delinger og kommentarer) er dog væsentligt i sig selv, da det viser noget om, hvor engagerende den enkelte politiker er. Vi kan også gætte på, at højt engagement medfører højere reach via algoritmisk synlighed, men selv Facebook advarer mod at sætte lighedstegn mellem engagement og reach (læs mere her). Crowdtangle er således et glimrende værktøj til at skabe overblik over siders aktivitet og engagement, men det er omvendt væsentligt at være opmærksom på begrænsningerne ved denne data, og dermed hvad vi ikke kan se og konkludere på basis af dette.
From https://blog.gaijinpot.com/spot-the-kanji-for-good-and-evil-in-everyday-japanese/
Whether your point of reference for the title of this piece is late 19th century German philosophy or early 21st century computer games, the implications are the same: The categories are blurred and, hence, we need to develop new modes of ethical judgement. This is particularly true now, as the need for such judgement is also moving beyond ‘the human’ and ‘the technical’ as separate realms. What we need, today, is a sociotechnical ethics that enable us to steer current developments in new directions. We need, to borrow from the subtitle of Nietzsche’s work, a new ‘philosophy of the future’.
Turning
from such sweeping visions to the more mundane question of how to introduce
data ethics to students, the aim of this post is to report on one small
experiment with technology-supported in-class debate.
Discussing
algorithms and data in the class room
Using Kialo as the platform for the debate, I asked my students to help develop and assess arguments pro and con the societal impact of ‘big data’. The students had been given a prompt in the form of boyd and Crawford’s (2012) ‘Critical questions for big data,’ and prior to the exercise I had pointed to a key quote from that text (p. 663):
Will large-scale search data help us create better tools, services, and public goods? Or will it usher in a new wave of privacy incursions and invasive marketing? Will data analytics help us understand online communities and political movements? Or will it be used to track protesters and suppress speech? Will it transform how we study human communication and culture, or narrow the palette of research options and alter what ‘research’ means?
Translating
these broad questions into more specific positions on the ethical implications
involved, students were then asked to produce arguments for and against four common
claims with clear tech-optimistic or tech-pessimistic valences as well as one
claim suggesting the irrelevance of big data:
Society
will become safer
Society
will become more controlled
Society
will become richer
Society
will become more unequal
Society
will remain unchanged
The
students were asked to provide one argument for or against each claim, and at
the end of the exercise we held a plenary discussion to reflect on the arguments
produced.
Students’
positions on data ethics
Looking at
the students’ arguments, a first finding is that no one argued in favor of the
claim that ‘society will remain unchanged’. To the contrary, the students
provided arguments against this claim, e.g. suggesting that corporate actors
and public institutions ‘will increasingly organize around big data’, that
‘techgiants have more knowledge about us, than we do’ and that individuals
‘will change their digital behaviors to protect their private lives’.
Beyond the
consensus that algorithms and data are impacting the social world, however,
students were divided as to the nature of the impact. And for each of the four remaining
claims, they produced approximately as many arguments in favor as against. For
instance, the claim that society will become more controlled, which was the
claim that produced the most responses, let to a nuanced discussion concerning
the implications of such control. That is, while most students took increased
surveillance for granted, some felt this to be a cause for celebration rather
than concern as it could ‘reduce crime’ or ‘create safety and make things
easier’. Others, however, highlighted the risks of ‘misuse’ and ‘manipulation’,
and suggested that people might self-regulate because ‘we do not know when we
are being watched’.
Interestingly, the students produced somewhat different arguments for the claim ‘society will become safer’, suggesting that control and safety might not be exclusionary categories, but instead exist in a trade-off. Here, students were less prone to accept the possibilities of data to produce safety and more concerned with the price of such safety, e.g. suggesting that lack of transparency creates uncertainty and arguing that the ‘need to produce regulation about data security [GDPR] shows that there is a problem’. Generally, however, for this claim the students felt that ‘it depends’. And one comment on the claim of ‘more control’ nicely sums up the general attitude:
…learning more about human action and behavior can be both good and bad. Depends on what one wants to control.
Turning to the question of growth, students clearly saw the potential of technological developments to create new business opportunities and increase the efficiency while decreasing costs of e.g. marketing activities. However, as one student argued:
…society might not need more growth and wealth, but a better distribution of resources.
This takes us to the claim concerning increased inequality, which students seemingly view as a side-effect of growth. That is, the students tend to support the combined claim that current uses of algorithms and data simultaneously produce more growth and more inequality. The reasoning being that ‘data is a form of capital with which you can negotiate’ and ‘the most powerful people and organizations have more access to data and can use it to their advantage’.
Towards
data ethics
In our
plenary summary of the exercise, the students reported that in considering
where to position themselves they had found that it is not easy to take one
stance or the other, as there are many arguments for and against all positions
and the matter is ‘more nuanced than I thought’, as one participant said.
Illustrating
this point was the main pedagogical aim of the exercise, which I concluded with
a slide showing Kranzberg’s (1986: 545) famous dictum that ‘technology is
neither good nor bad; nor is it neutral.’ However, I also hoped to move beyond
the articulation of this position to begin developing the alternative. What
might a data ethics beyond the clear dichotomies of optimism and pessimism –
good and evil – look like?
In reflecting on this question, we talked about intentionality, consequences, and situationality. Each of these potential principles of judgement are reminiscent of well-established ethical schools and, hence, carry with them the same issues of when and how to use either. As might be expected, we did not resolve these issues once and for all, but the questions linger with me – and, I hope, with the students.
With this text, I invite continued reflection on the ethics of data in as well as outside of classrooms. The future will not wait for us to develop a new philosophy, and, hence, establishing a robust and distinct data ethics is an increasingly urgent matter.
Digital Media Lab har denne gang undersøgt den poliske debat før, under og efter Regeringens pressemøde den 7. maj samt partilederdebatten den 14. maj i forbindelse med COVID-19 og fase 2 af genåbningen af landet.
Pressemødet d. 7. maj
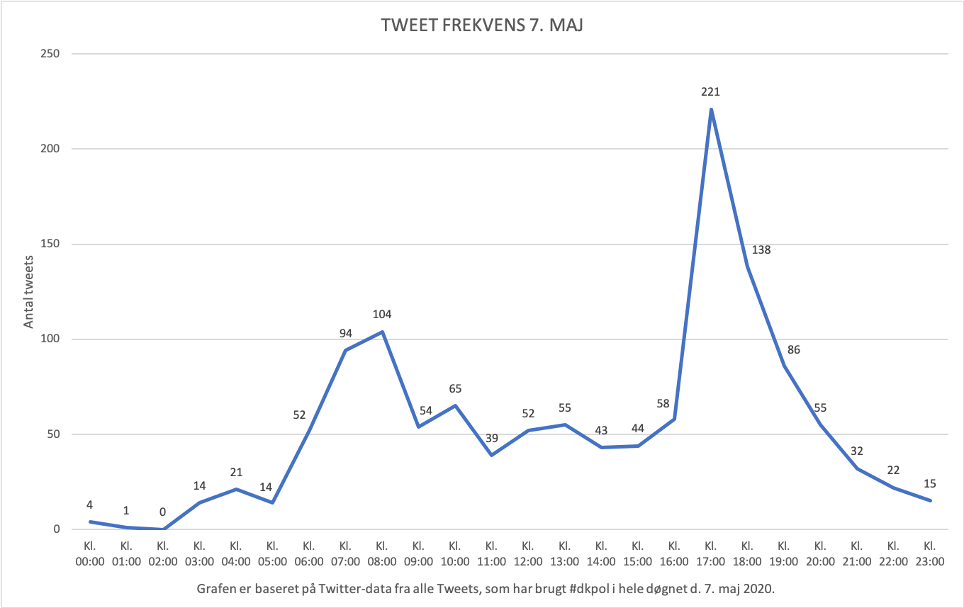
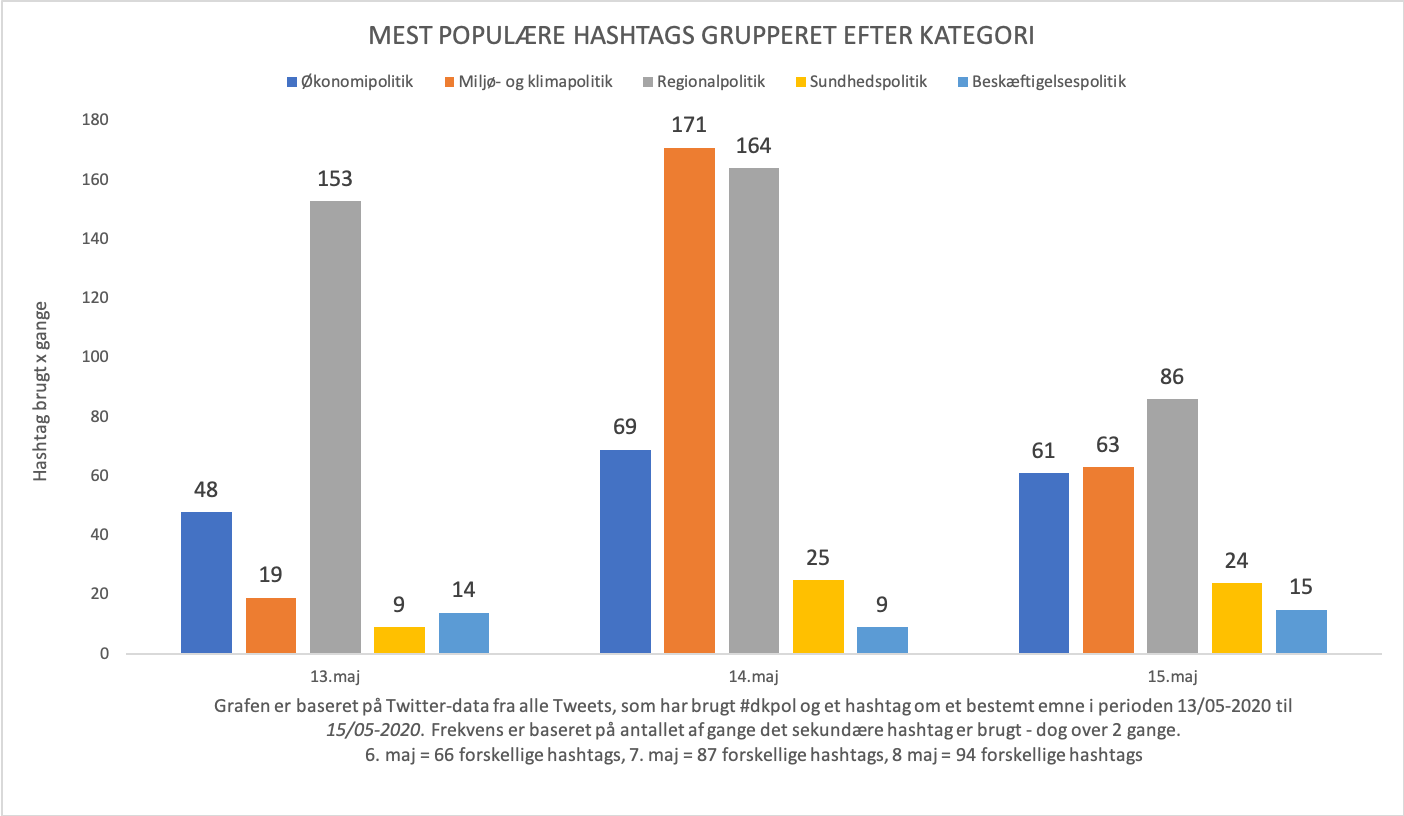
Efter en hel dags forhandlinger med folketingets partiledere trådte Mette Frederiksen frem i Mariensborgs have for at fortælle, hvad der var blevet lavet en bred politisk aftale om. Vi har kigget på hvilke hashtags, som var de mest brugte på Twitter i denne periode. Disse hashtags har vi inddelt i fem politiske kategorier, som hver rummer forskellige grupper af hashtags.
Grafen viser hvilke politiske emner, som der på Twitter blev omtalt mest i tre dage fra den 6.-8. maj via det populære politiske hastags #dkpol, som bruges til at diskutere politik i Danmark. Selve pressemødet var den 7. maj, så giver denne graf overblikket over de centrale hashtags dagen før, under og efter pressemødet. X-aksen viser antal gange et hashtag under den politiske kategori er blevet brugt i et tweet sammen med #dkpol. Hvis man eksempelvist skriver i et tweet ”Den grønne omstilling er vigtig! #dkpol #dkgreen #dkklima så vil de Miljø- og klimarelateret hashtags tælle som to under Miljø- og klimapolitik-kategorien nedenfor i grafen.
Kategorien ’Økonomipolitik’ dækker over hashtaggene #dkbiz, #dkøko og #dkfinas.
Kategorien ’Miljø- og klimapolitik’ dækker over hashtaggene #dknatur, #dkgreen, #dkklima, #plasticchange og #actonclimate
Kategorien ’Regionalpolitik’ dækker over hashtaggene #eu, #svpol, #nopol , #fipol, #dkeu, og #deutschland
Kategorien ’Sundhedspolitik’ dækker over hashtaggene #sundpol, #bedrepsykiatri og #tørdublivesyg
Kategorien ’Beskæftigelsespolitik’ dækker over hashtaggene #arbejde og #dkjob.
Dagen inden pressemødet ses det tydeligt, at det er regionalpolitik, som var det store omdrejningspunkt. Regionalpolitik er i denne sammenhæng debat omkring grænseåbningen ved de omkringliggende lande. Der bliver i høj grad diskuteret hvorvidt grænsen mod Tyskland skal åbnes, så de tyske turister kan besøge Danmark, men også om der skal være adgang til Danmark fra Norge, Finland og Sverige. Derudover bliver der også diskuteret hvilket land, som har håndteret coronakrisen bedst. Det samme gør sig gældende dagen efter pressemødet, hvor det ses at økonomipolitik er nævnt mere end dobbelt så mange gange som miljø- og klimapolitik. Ydermere ses det også, at økonomipolitik fyldte meget på dagen for pressemødet. Det kan skyldes, at Mette Frederiksen præsenterede en bred aftale, som gjorde at detailhandlen og restauranter kunne åbne igen.
På dagen var det samtidig også tydeligt, hvornår der blev tweetet mest. Det skal dog nævnes, at denne data er taget fra hashtagget #dkpol. Det er således også primært politiske kommentatorer, journalister og andre politikere, som reagerer på pressemødet og bruger hashtagget dkpol i tidsrummet omkring pressemødet.
Partilederdebat den 14. maj
Efter at have annonceret en aftale om genåbning, så arrangerede tv-kanalerne TV2 og DR en fælles partilederdebat sendt fra Statens Museum for Kunst. Debatten havde navnet ‘Hvordan får vi Danmark tilbage’. I den forbindelse har vi lavet samme undersøgelse om partilederdebatten som ved pressemødet den 7. maj.
Grafen viser hvilke politiske emner, som der på Twitter blev omtalt mest over perioden 13.-15. maj.
I dette diagram er det tydeligt at se miljø- og klimapolitikken dagen inden ikke var et særlig diskuteret emne, men på dagen for partilederdebatten var det, det mest omtalte emne. Derudover var regionalpolitik dagen inden og på dagen for partilederdebatten meget omtalt på Twitter, men også dagen efter – dog ikke i et så højt et tal som de to andre dage. Det er ligeledes bemærkelsesværdigt, at miljø- og klimapolitik ikke er højere den 15. maj, da der blev vedtaget en bred politisk aftale om klimatilpasning.
Man kan derfor konkludere, at regionalpolitikken og miljø- og klimapolitikken på dagen for debatten var de mest omdiskuterede emner på Twitter. Det er samtidig bemærkelsesværdigt, at miljø- og klimapoltikken bliver diskutere over dobbelt så mange gange som økonomipolitik. Det er ligeledes bemærkelsesværdigt, at der ikke er omtale af miljø- og klimapolitikken, i det aftalen om klimatilpasning blev vedtaget, men dette kunne skyldes, at aftalen var bredt indgået af regeringen, Venstre, Konservative, Radikale, SF, Enhedslisten, DF, og LA, hvilket således gav mindre anledning til politisk debat og kritik.
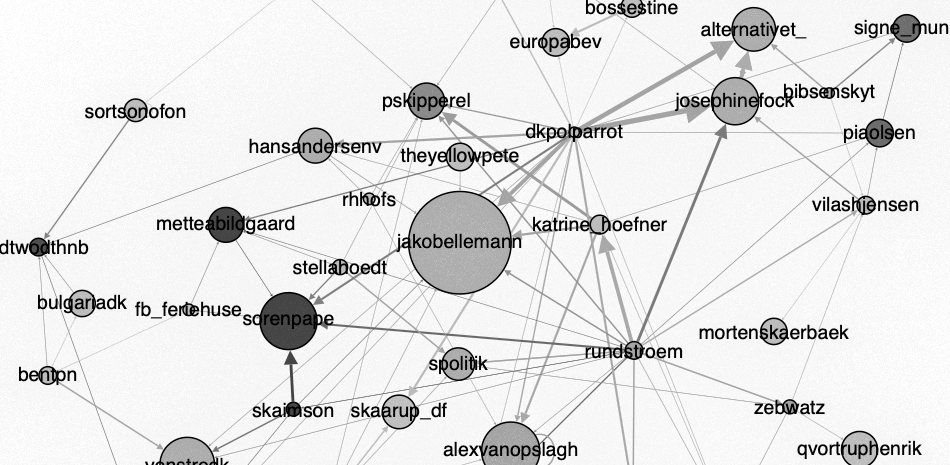
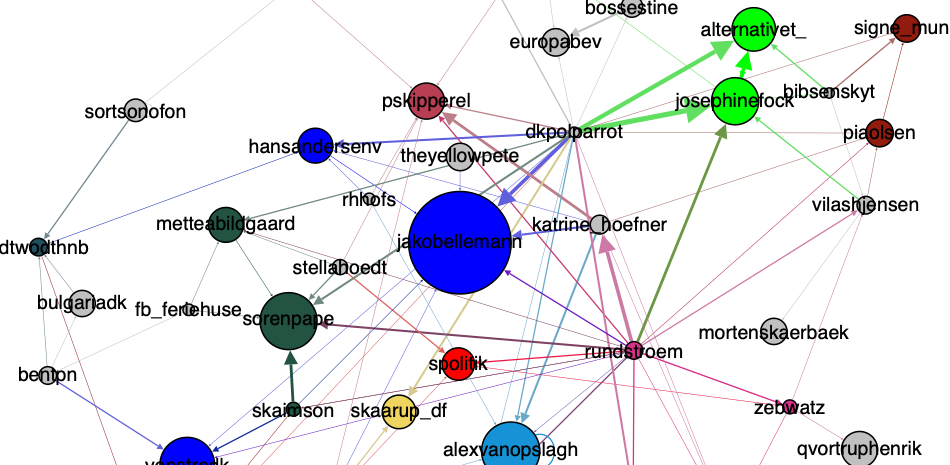
Vi har derudover også lavet en netværksgraf, hvor man kan se hvilke profiler som blev nævnt mest og er mest centrale på Twitter i løbet af hele dagen den 14. maj, hvor partilederdebatten fandt sted. Profiler fra politiske partier er farvet med partiets farve. For at blive præsenteret på netværksgrafen skal man være nævnt 10 gange eller mere eller nævne en anden 10 gange eller mere. Nodernes størrelse er desuden også baseret på antal af @mentions, det vil sige at noden er større, hvis profilen nævnes mange gange.
På netværksgrafen ses det, at Jakob Elleman-Jensen er den mest centrale og største node efterfulgt af Alex Vanopslagh, Venstredk og regeringdk. Det ses ligeledes, at der er flest noder i netværket fra den radikale gruppe, da der i netværket er fire noder med de radikales partifarve. Man kan ligeledes se, at både Pernille Skipper og Peter Skaarup er de eneste repræsentanter for deres parti, som er nævnt over 10 gange. De grå noder er private aktører, som ikke var muligt at identificere som offentlige eller politiske aktører.
Ud fra ovenstående analyser, er det muligt at konkludere, at debatten på Twitter i høj grad handler om at åbne landet mere og hvilke konsekvenser det har, hvis det ikke sker. Dette er således mere dominerende end debatten om sundhed eller de problemer, som der er ved de antal arbejdsløse danskere. Derudover ses det også, at det i høj grad er Jakob Elleman-Jensen som løber med opmærksomheden på Twitter. Dette kan skyldes, at både Jakob Elleman-Jensen og partiet Venstre forsøger at positionere sig synligt som oppositionen, der således forventes at stille de kritiske spørgsmål til Mette Frederiksens og regeringens planer for genåbningen af Danmark.
The technological development has in recent years given us more and more opportunities to access, create and store data about ourselves and others. We communicate online with family, friends, acquaintances and people we do not know at all. We follow people, companies and organizations as well as hashtags online. We share thoughts, opinions and ideas in cyberspace together with our whereabouts, selfies and photos of others, and the things we do and buy. We register our sleep, steps, meals and temperature. And while we do all of that – and more – we leave digital traces behind – knowingly or not.
Together, these traces create an
unprecedented amount of social data. Data that forms a goldmine for researchers
in social science – like myself and my colleagues, and probably also you, dear
reader, as you are reading this blog.
It is easy to become euphoric when thinking of the amount of data that the technologies are generating and giving us access to. Think about the insights we can create on how viruses travel and spread across boarders or how student socialize and learn online. Knowledge that can help us build better health services and stronger educational systems. But the opportunities come with ethical challenges. Because is the data actually ours to collect, store, share and analyse in the name of research, just because it exists and is accessible? Or does the data belong to the individuals who created it and should they be consulted before we use it?
I have no clear answer to this question, but I think it a crucial one. Therefore I have been looking around for help and guidance.
I began my search by looking into the infamous GDPR, the extensive piece of legislation that was adopted in April 2016 by the European Council and Parliament. This piece of legislation seems to work well for private companies, but is not very helpful for me as a researcher looking for ethics. I am no legal expert, but from reading people who are, I understand that research occupies a privileged position within the Regulation: “Organizations that process personal data for research purposes may avoid restrictions on secondary processing and on processing sensitive categories of data (Article 6(4); Recital 50). As long as they implement appropriate safeguards, these organizations also may override a data subject’s right to object to processing and to seek the erasure of personal data (Article 89). Additionally, the GDPR may permit organizations to process personal data for research purposes without the data subject’s consent (Article 6(1)(f); Recitals 47, 157)” (see: https://iapp.org/news/a/how-gdpr-changes-the-rules-for-research/)
My own conclusion: Good to know what the rules are, but not the right place to look for ethical guidance.
So, looking for ethics, my next stop, was the homepage of the Danish ‘Council of Data Ethics’ (Dataetisk Råd). The council was established in May 2019 by the government with the stated task of supporting ‘a responsible and sustainable use of data in the private and the public sector’ (see: https://digst.dk/data/dataetisk-raad/). It would seem to be an obvious place to find some guidelines but turned out to be another dead-end. On the homepage, the council writes that it is essential that the data ethical challenges of the public sector are addressed, but at this point in time they have only prepared recommendations directed at the private sector.
Finding no help with the Council
of Data Ethics made me think that I might need to change my search.
Instead of looking for ethical guidelines concerned with the use of personal digital
data in social research, perhaps I should be looking for guidelines developed
for health and medical researchers as this group has been dealing with ethical
issues connected to working with sensitive and personally
identifiable data for years. Maybe there was
something to learn from our colleagues?
In the following, I will extract some central points of the statement and discuss their relevance and how they might help inform a similar discussion in the field of social science.
Personal ownership and consent
First of all, the publications underline that medical science is based on a 400 years old liberal tradition where every person is believed to have ownership of their own body and all information connected to it – in a medical context meaning tissue, bioproducts and genetic information et cetera.
I think this opens up an interesting discussion in relation to the data we create about ourselves online. Could and should we understand the data that is produced online in line with data derived from our physical body and as such place it under the banner of personal ownership?
If we were to accept the idea that every individual owns the data they produce online, the next step according to the Ethic Council would be for researchers to ask for ‘informed consent’ from the data owners when we want to use their data. In doing so, we should enable the data owners to decide not only if the data can be collected and by whom – but also which purposes it can be used for.
Having to ask for consent might seem inarguable when you want to drain human blood or take a biopsy from person’s liver, but when the data is accessible and can be collected with a webspider that no one sees or feel it might become easy to think of the data as finders keepers?
Anonymity, privacy and confidentiality
The ethical imperative behind having to ask for consent from the data owners is the idea that people have the right to autonomy and self-determination. Meaning that people should be free to decide whether their personal data is used in ways that are aligned with their personal values and beliefs. If there is no alignment it could be claimed that the autonomy of a person has been violated. In health research we might agree to our data being used to do research on a rare eye disease but not for anything connected to euthanasia. I think the same considerations could be pertinent in relation to social online data, where it would be possible to imagine cases where the focus of the research is not aligned with the values of the individuals producing the digital social data used in the study. On could imagine a study focused on political differences between men and women, that a person who does not subscribe to the idea of a binary biological gender might take affront to and therefore would not wish to contribute their data to.
Further, the Ethic Council states in its report that it is often assumed unproblematic to use anonymized personal data in research. But if one applies the idea of autonomy and self-determination, it is no longer possible to think of it as unproblematic, as a person’s personal values and believes can still be violated even though the data can’t be traced back to an individual level. Furthermore, there is always a risk that the data is not thoroughly anonymized and it can therefore be argued that it should be the individual data owners themselves who decide if they find it sound to provide their data to a research project.
Solidarity and public interest
There is no doubt when reading the reports from the Ethical Council that they are concerned about people’s data and their right to self-determination, anonymity and privacy and that they advocate that we as researcher ask for consent before collecting and using personally identifiable data. With that being said, the Ethical Council points to the importance of enabling researchers to build knowledge that is of societal value – even though this can be undesirable for the individual. The argument goes that in order to be able to heal and help people, health researchers need the ability to access personal information. A cure for cancer can’t be created on basis of theoretical hypotheses only, but demands blood, sweat and tissue from many individuals. Therefore, we as individuals must show solidarity and put the collective interest before our own – even when we pay with our private data. I believe that the same could be argued for social research. Access to data – including sensitive personal data – impacts the knowledge we are able to build. The key question is when the knowledge is of such an interest to the public that we can justify using the data. Is it when data helps us make informed decisions on how to diversify the way we teach in order to meet different learning styles? Or is it when we use data to predict who will pass and fail a study and base our admissions of students on such predictions? I am afraid that there is no simple, clear-cut answers to such questions.
What now?
I started out by asking if online social data is ours to collect, store, share and analyse in the name of research just because it exists and is accessible? Or if it belongs to the individuals who created it and who we need to consult before we can create, collect and use the data?
Neither the legislative texts of the GDPR, nor the reports from the Ethical Council, give me any strict guidelines, but I do think that they call for a larger awareness of and discussion in the social science research community on how we should deal with public and private data and how we make sure to consider and deeply reflect on whether what we do as researchers is of such a nature and interest to the public that we can justify collecting and analyzing sensitive personal data regardless of the relative ease with which we can access it online.
We can make rules and laws like the General Data Protection Regulation (GDPR) but in the end the matter also has to do with trust. Does the public trust us researchers and the institutions we represent to such a degree that they are willing to grant us access to their cells and internal organs as well as their (secret) desires, habits, ideas and opinions expressed online? Earning, having and keeping that trust – now and in the future – depends on how we think about and handle sensitive personal data today. It is a discussion we have to engage in. Together. So, what are your thoughts?
Mette Wichmand is an Assistant Professor of Communication Studies at Roskilde University
Misinformation has been a theme in recent years in connection with several democratic elections in our neighboring countries. In particular, the notion of ‘fake news’ with fictitious and factually incorrect stories has received much publicity. However, experience from countries such as the UK, Germany and Sweden had already shown that so-called ‘junk news’ is more widespread that actual misinformation from foreign actors or trolls interested in corrupting the election results. Therefore, Politiken set out to investigate the phenomenon in Denmark prior to the parliamentary elections in the spring of 2019. The newspaper contacted Digital Media Lab in the initial research for this story, as a number of questions came up during the research.
First of all, how could previous research carried out during
elections in Sweden be used in a Danish context?
Researchers at Oxford University had already investigated the phenomenon. They defined ‘junk news’ as ‘propaganda and ideologically extreme, hyper-partisan or conspiratorial political news’. Five criteria were used to measure the amount of junk news during the election. Oxford examined the Swedish election in the fall of 2018 and concluded that for every three normal articles shared on Twitter, a ‘junk news’ article was shared.
The Oxford researchers were not investigating the general election in Denmark. Politiken therefore set up an expert panel with the help of the three journalism programs in Denmark. I agreed to be part of the panel, together with Peter Bro, head of the Center for Journalism at the University of Southern Denmark, Vibeke Borberg, lawyer and associate professor of media law from the Danish School of Media and Journalism.
New questions came up and simply employing the framework from the Oxford study proved an uneasy fit.
The panel spent quite some time discussing the definition of ‘junk news’ and after reading several of Oxford’s reports we concluded that the Oxford criteria were deficient. Instead, the panel set out 20 criteria for how we would assess what ‘junk news’ is. We decided that it was important to evaluate 1) The platform 2) the producers and 3) the product.
In terms of platform, we developed criteria such as ‘who
owns the medium?’ And ‘is the business model transparent?’
As far as producers are concerned, the panel decided to include criteria such as ‘does the media correctly declare article genres, such as news and attitude?’ And ‘Is the media willing to correct mistakes, and how does it make the readers aware of corrections?’
As far as the product was concerned, the panel wanted to
include criteria such as ‘does the media follow the contradictory principle –
that the accused in an article has the right to see and respond to criticism?’.
Another criterion, although a difficult one, was: ‘Is the information
communicated by the media outlet misleading?’
The panel chose to focus on new digital media. The criterion for becoming part of the study was for the media site to refer to themselves as ‘media’, who did ‘journalism’ or ‘news’, or had a set-up reminiscent of news media. Party political media and actual blogs were cut off from the study as they were considered to be a category for themselves. It would later prove to be somewhat difficult to distinguish between news sites and blogs for example.
Against this background, Politiken located 15 media sites that the expert panel could examine. Articles from the 15 sites were collected during the same study period, 25. February- 4. March, whenever possible. For the most productive sites, Politiken stripped away reader letters, Ritzau articles, debate posts and daily reports from the police, so that the expert panel would only review editorial production.
The prevalence of junk media on social media was investigated with a so-called Twitter Capture and Analysis Toolset (TCAT). This tool is available from Digital Media Lab at Roskilde University. (You can read more about TCAT here).
So, what did we end up with? How much was junk and was junk news really a problem?
The expert panel reviewed a total of 237 articles from 15 media sites. The panel concluded that nine of the media produced journalism of such poor quality that they could be defined as junk news sites. Those nine media were: 24News, NewSpeak, People’s Newspaper, The Short Newspaper, Today’s, News24, Digital News / Hug, dkdox.tv and 24/7.
Six media were assessed by the expert panel to NOT be junk
media. They were: 180 Degrees, NewsBreak, Document, Solidarity, Updated and
Responses. The experts’ reasons differed depending on the media. Some provided
content of a quality that was satisfactory. Other media were considered by the
panel to be blogs or social media, not news media. Therefore, they were not
relevant to the investigation, the panel believed.
The research concluded, that several Danish digital media were spreading misinformation and hidden advertising on the internet. Their articles look like real journalism, but contain misleading information to such a degree that it can be seen as a democratic problem.
As part of the expert group, I warned against these sites as they are advertising and propaganda disguised as news journalism. It can be a democratic problem if these media manage to influence the Danes’ attitude toward certain political issues.
By doing this analysis, Politiken was able to show that doubtful
articles from so-called junk media not only set the agenda on social media.
They are also involved in the parliamentary processes, where politicians
question the Ministers based on misleading information.
It is common to refer to specific stories in the news when
asking a question to a minister, and Politiken found that 69 questions during a
period of two years were based on stories published by sites characterized as
junk news. This led to a broader discussion of which media sites to refer to and
the responsibility of ministers and politicians to check the information of the
sites they refer to, before citing them.
The project was nominated for an investigate price for the innovative method by the Danish Federation of Investigative Journalism (FUJ), 2019.










 By Mette Wichmand
By Mette Wichmand
 By Jannie Møller Hartley
By Jannie Møller Hartley