Unique opportunity for anyone interested in digital media and research.
Here in the Digital Media Lab at RUC we collect data from digital platforms and develop novel computational methods using GenAI, network analysis and digital ethnography.
Join us in one of Denmark’s best research environments according to Det Unge Akademi.
We are looking for two student assistants for 2026-2027. Application deadline 9th August.
How did Danish alternative media cover the 2026 Danish general elections? In our fresh new lab report, we analyse 928 articles from 14 different alternative news outlets. The report suggests that Danish alternative media presented different versions of the election campaign. Left-leaning outlets mainly focused on welfare, labour and parliamentary power, while right-leaning outlets more often connected the election to borders, culture, media power and national direction. Furthermore, alternative media help determine the emotional and thematic terrain on which parts of the electorate encounter the election. They do not just report the campaign; they sort it, sharpen it and give it political meaning for distinct publics.
The report comes out of the AlterPublics project funded by Carlsbergfondet and is based on data from the Nordic Alternative Media Observatory hosted in the lab.
Time: 15 April from 12-13 Place: Digital Media Lab, room 40.3.45, Roskilde University
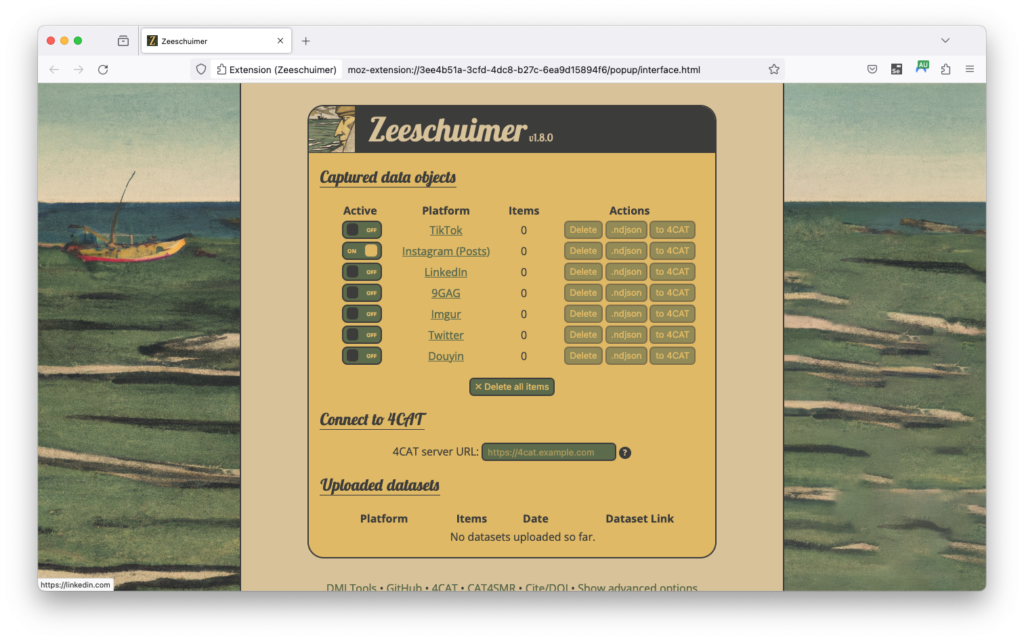
Frederik Henriksen introduces Zeeschuimer, a user-friendly tool for collection of social media data (e.g., TikTok and Instagram) developed by the Digital Methods Initiative (University of Amsterdam).
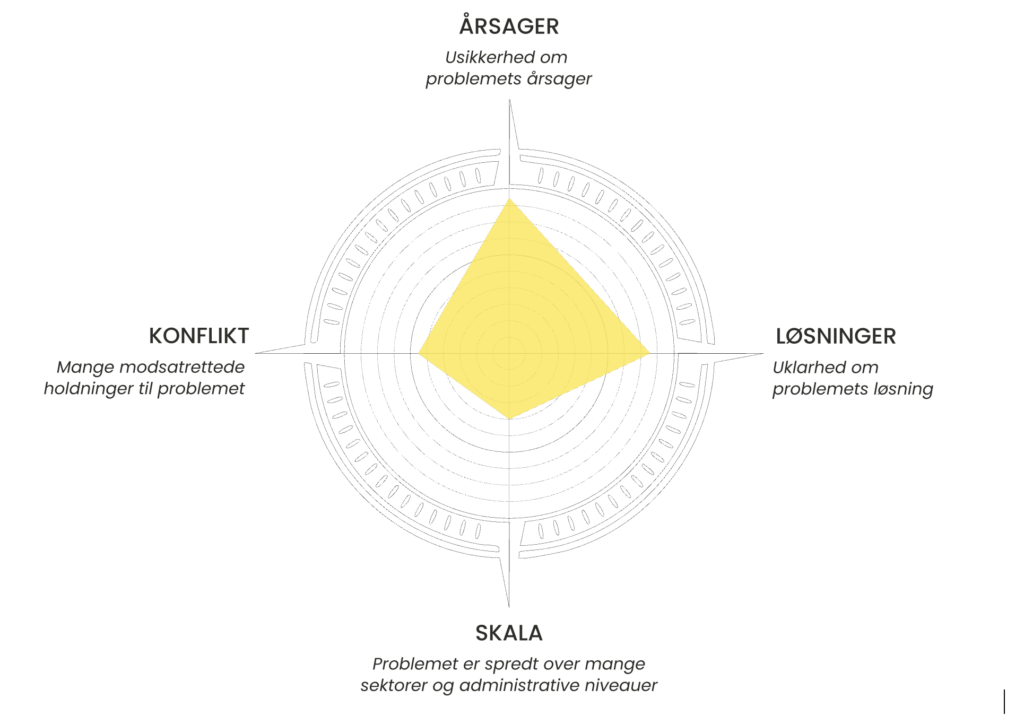
Sofie Thorsen and Sam Rahbar from the Institute for Wicked Problems (INVI) present their Involve tool for democratic innovation and their associated AI-driven model for measuring the wickedness of public problems.
All welcome – no registration needed – please share
Søren Pedersen (independent AI-developer) presents his ongoing experiments with using AI for ‘live’ detection of political bias in online news articles. Among other things, Søren has measured 500 articles from dr.dk. He also made a browser extension tool called “Politisk Biasmåler” publicly available. After his talk and the Q&A session, Søren will also be available for more detailed technical discussions.
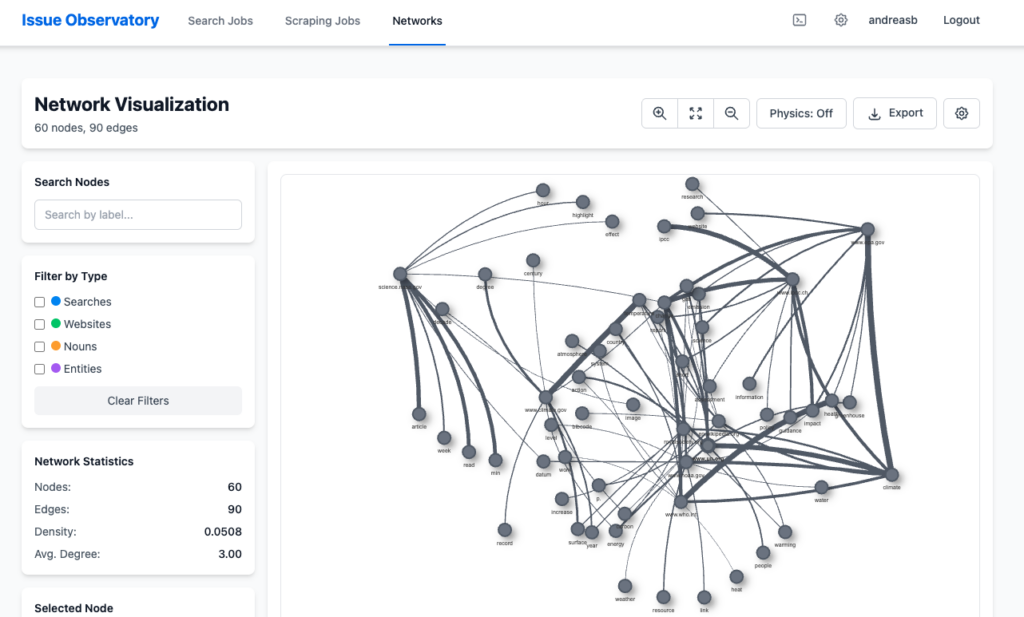
Jakob Bæk Kristensen (RUC/Digital Media Lab) presents our new Issue Observatory tool, a prototype for harnessing search engine data and applying network analysis to track how public actors position themselves on various issues. Logins can be provided to all attendees.
Bring your lunch and expand your digital methods horizon!
Tool Lunch – bring your lunch and expand your digital methods horizon
26 November 2025 from 12-13 in room 40.3.045
Postdoc and lab member Leif Hemming Pedersen presents the Data Donation Module, an open source web application that facilitates the collection of data donations for academic research, developed by The Data Donation Lab at University of Zurich
NEW DATE: 20th November 2025, from 13.00-15.00 in room 40.3.45
Would you like to try a bit of digital methods yourself? Unsure how to get started? Consider joining this Digital Media Lab workshop, led by postdoc Frederik Møller Henriksen. No prior skills needed, just bring your laptop. Both students and colleagues are most welcome. Snacks and drinks will be served.
If you have any questions, please contact Frederik on frmohe@ruc.dk
If you would like to participate, please register by 18 November to frmohe@ruc.dk
29 Oct 12-13 in Digital Media Lab, Roskilde University, room 40.3.045
Tool Lunch – bring your lunch and expand your digital methods horizon
ManuScrape er et brugervenligt værktøj, der gør storskala netnografisk forskning tilgængelig for alle. Det er udviklet af MOD-lab og CodeCollective som et specialbygget redskab til dataindsamling i MOD-labs projekter. Med ManuScrape kan du uden besvær indsamle, berige og analysere data fra platforme som Discord, Facebook, Instagram og andre webbaserede medier. Du kan dokumentere visuelle interaktioner, tilføje noter, kode data samt sikre datasikkerhed gennem anonymiseringsfunktioner, så GDPR-overholdelse fastholdes.
Professor i sociologi ved KU, Jakob Demant, gennemgår hvorfor programmet blev udviklet, herunder den open source-proces, som det er skabt gennem. Vi ser nærmere på de centrale funktioner via en demonstration. Desuden afholder vi en kort workshop, hvor deltagerne får hands-on erfaring med værktøjet. Der vil bliver cirkuleret et paper om programmet (in review) og man er velkommen til at downloade og afprøve/anvende det!
Programmet bygger på forskningsprincipper om mindst mulig indgriben, idet det registrerer observationer på en måde, der afspejler state of the art i samfundsvidenskab, digital humaniora samt NGO’er, medier og andre, der studerer onlineadfærd. ManuScrape er udviklet efter open source-principper, hvilket betyder, at kildekoden frit kan ses, modificeres og videreudvikles. Denne gennemsigtighed styrker både tilliden til GDPR-overholdelsen og muliggør samarbejde og innovation. Dermed sikrer vi, at ManuScrape forbliver tilgængeligt, pålideligt og i løbende udvikling.
Programmet er også en stor hjælp hvis man ønsker at gøre sine kvalitative observationelle data tilgængeligt i et OpenScience format for andre forskere.
Det pibler frem med nye danske sociale medier for tiden. Fælles for dem er, at de vil befri os fra big tech og gøre verden til et lidt bedre sted. Meningspunktet.dk er et af disse initiativer. De vil afløse Facebook på den centrale plads i det danske samfund og skabe forbindelser i nærmiljøerne, uden at brugernes data sælges, og uden at algoritmer styrer opmærksomheden. Vi får besøg af Meningspunktet.dk, som fortæller om visionen og om hvordan det går med at udføre den i praksis.