We are currently attending the European Investigative Journalism Conference (EIJC19) in Mechelen, and will write about interesting software usable for research purposes.
This list of software is something we took a note of, and that you might find interesting.
- Datashare – a cool piece of software for reading documents and turn unstructured data into structures.
- Neo4j – Graph software, that turns relational data into just that – relations, that can be visualized in many ways. Using a language quite similar to SQL. Syntax is pretty complex though.
- Anaconda – Once again the Anaconda platform seems to be the weapon of choice for coders around the world.
- OSINT Framework – Framework focused on gathering information from free tools or resources. Also on Github.
- Python Package Index – Great overview of libraries. Searchable, obviously.
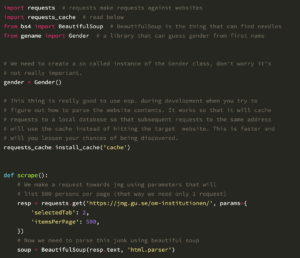
And as a small bonus, we did a bit of coding while at the conference. So we have updated our scripts for converting handles and id’s for Twitter users (and vice versa). Now they output both to command line and CSV-files 🙂